We’re going to be at the Fort Wayne Maker Faire this weekend. If you’re in the area come by and say hi!
We’re going to be at the Fort Wayne Maker Faire this weekend. If you’re in the area come by and say hi!
Our booth at the Detroit Maker Faire. We had a great time meeting people and showing off our stuff. There were a lot more people than the pictures might suggest, but I was busy talking to those people and only had a chance to snap pics during the lulls 🙂
Next, we’ll be at the Fort Wayne Maker Faire in a couple weeks.



We’ve been working on bringing our hypno-effects to string lights for some time now, and just launched a Kickstarter campaign to help fund our first production order! Check it out here: hypnocube.com/kickstarter



On several recent microcontroller projects I have needed to store settings in microcontroller flash, and since flash erase/write cycles are fairly limited, I had to pack bits carefully to ensure that gadget lifetimes would be usable. To increase flash lifetime, error correction codes are often used to mitigate flash failures, but different error correction codes work best for certain error patterns, so I wanted to test how bits fails in flash. Knowing details about bit failure modes, patterns, and related issues would help select an error correcting code that is most useful for my combination of needs and restrictions. I could not find the information I wanted, so I decided to test my devices. This article details the flash bit failures for the device I tested, and hopefully is useful for similar devices and designers.
To gather the relevant data, I wrote code that repeatedly erased/wrote flash memory, logging all bit failures so I could analyze them. Over a period of about a day and a half I gathered about 1 million erase/write cycles from microcontroller flash, logged over 40 million bit failures, learned quite a bit about flash memory in the process. The results are interesting and are the reason for this article.
Here is a screenshot showing the bit errors after the million erase/write cycle run. Details are below, and a video of it is at https://www.youtube.com/watch?v=7elfyRyW5ms.

Since flash degrades over time from erasing/writing (or even just reading, although that decay is slower), if the decay modes are understood, then error correction codes can be designed to improve the length of time before a system fails. However the two main error codes recommended, Reed Solomon and BCH codes, are suited for different failure patterns. Without getting into the details (that may be another article), Reed Solomon is more useful for bit errors that occur bursts, which BCH codes are better for bit errors that are uniformly distributed. (Informally, both work over finite fields of size 2^n, and RS codes correct field elements, i.e., n bits at a time, while BCH codes correct at the single bit level).
Another issue was the devices I was using listed erase/cycle lifetime of about 20,000 cycles, and I wanted to test some devices to see how accurate this is. Turns out the flash is likely useful for many, many more cycles than the spec sheet (conservatively) lists.
To help explain the results, it is useful to cover the physical level of flash storage. I will do it in two levels of detail, basic and advanced.
At the physical level, flash memory stores logical 0 and 1 as electrons trapped inside insulated cells. The electric field inside these cells are read by transistors that use the field strength to detect if the charge in the cell passes some threshold or not. Erasing flash is done by pulling the electrons out of the relevant cells using large voltage potentials, and writing is done by putting electrons in the cells, often through “hot electron” injection which is done by creating highly energetic electrons that can pass the insulating barrier. Over time these cells degrade through a combination of electrons getting trapped in the insulating materials, which makes the threshold hard to identify, and through physical damage to the cell from repeated hot electron injection. As the insulator breaks down, the charge no longer remains trapped. The end result is flash memory cells degrade over time.
If you’re comfortable with this level of physical representation of flash, skip ahead to the experiment. If you want a lot more physical details, read the next section on advanced flash memory operation.
Since I wanted this to be approachable to non-physicists/non-solid state people, I’ll explain how flash memory works starting at a very low level: atoms and electrons. I’ll try to cover briefly and mostly qualitatively how flash memory works from fundamental physics on up.
The net result of this section is materials can be created that have an excess or lack of electrons, which in turn affects how easily it is to get electrons to move through such materials, and that placing different materials next to each other can cause useful electron effects at the resulting boundaries.
Electron behavior is most accurately treated by quantum field theories (QFTs, the Standard Model in particular), which are a bit too abstract for this article, so I will treat electrons (incorrectly, but illustratively) as little balls with charge that orbit the nucleus of an atom, adding the non-classical behavior of being able to quantum tunnel through energy barriers. Electrons have a -1 charge, and each proton in the nucleus has a +1 charge. As described theoretically by QFTs (or less precisely by quantum mechanics), and as determined experimentally, electrons bound in atom orbits have discrete energy levels. Also as described theoretically and determined experimentally, opposite charges attract and like charges repel. These basic physics facts drive most of how solid state devices work (to get an accurate quantitative model takes a lot more quantum mechanics and solid state physics, but this simple level gives a good understanding).
Electrons on a single atom are allowed to take discrete energy levels, and through the requirements from spherical harmonics, these energy levels can be computed and described quite accurately. Spherical harmonics are simply the math giving solutions to which periodic waves have spherical symmetry. From this math the electrons form energy “shells” and “subshells,” which are just useful ways to classify the different electron energy levels. The outermost shell (with some exceptions) interacts with other atoms to form larger structures.

(The most common isotope of) silicon, for example, has 14 protons, 14 electrons, and 14 neutrons. The electrons are arranged in three shells containing 2, 8, and 4 electrons in increasing energy levels, with the nomenclature 1s^2 2s^2 2p^6 3s^2 3p^2. The initial number in each term denotes the shell, the ‘s’ and ‘p’ denote subshells (names are from historical messiness), and the powers denote the number of electrons in each subshell. That the outer shell has exactly 4 electrons is very important for semiconductors. Ignore the ‘k’,’l’,’m’ in the diagram.
Atoms bond with each other to form larger structures by trying to form lower energy states, which includes trying to fill electron shells and/or taking electrons from atoms that have weaker hold on them (with the resulting + and – charged ions then forming ionic bonds). A common bond type in semiconductors is the covalent bond: neighboring atoms share electrons to try and fill their outer shells with 8 electrons.
As atoms form solids, electrons interact and “smear” across larger regions, causing the allowed energy levels to “split” into refinements. The net result is there are still discrete energy levels, but they tend to come in bunches, forming what are called “bands” and “gaps” in solid state physics. Bands are where there is a dense collection of energy levels, and gaps are an energy range where there are no allowed electron states.
When the system is at the lowest energy state (absolute zero temperature, for example), the electrons tend to stay in the outer shell, called the valence shell. The resulting energy levels are the valence band. As temperature increases, or voltage (explained below) is applied, more and more electrons leave the valence band for higher energy states, called the conduction band, and this movement allows electric current to flow.
Just like a gravity field is a force that attracts mass, an electric field is a force that attracts (or repels) electric charge. The strength of a gravitational field is similar to voltage: a stronger gravitational field causes masses to accelerate more, and a higher voltage causes an electric charge to accelerate more. This is needed to understand how electrons are moved about in semiconductors, and in particular, flash memory.
The higher view of electricity using volts, amps, and ohms, can all be modeled using how electrons move in solids. Current is the flow of electrons, with an amp denoting the movement of one coulomb of charge per second past some point. A coulomb is a quantity of charge containing 6.241×10^18 electrons. Voltage measures the potential difference between two points, and gives the force that pulls at each electron. One volt can be defined as the potential difference between two infinite parallel conducting plates 1 meter apart that creates a force of 1 Newton per coulomb. Double the volts, and I doubles the force. For scale, 1 Newton is roughly the force of gravity at Earth’s surface on 102 grams.
Intuitively, voltage is how much force is pulling on electrons, making them move, and current is how many move per unit time.

Different materials allow electrons to move more or less easily, and the ease of movement is called conductivity. Conductivity is defined as the current (in amps per square meter) divided by the electric field strength (in volts per meter). The reciprocal is resistivity. Many factors influence conductivity, such as how many electrons are in outer shells of a material, how strongly they are held, temperature, etc.
In some materials, the outer (valence shell) electrons are tightly held in the atoms or molecular structure, and the high potential required to make them move results in electrical insulators. In other materials the valence electrons move much more easily, making conductors. This can all be computed from basic electron structures with enough magic.
The ease that materials allow electrons to move about in the presence of an electric field is called conductivity, and the reciprocal is called resistivity. At a given voltage (think gravitational pull for charges), a more conductive material will allow more electrons to flow, and the rate of electron flow (the flux) is called current. Increase the voltage, and the current will increase. All of this is somewhat simplistic, but accurate to first order, and illustrative of how devices work.
The image shows energy levels for a few types of materials.
Elements are organized in the periodic table into columns that give a first approximation to outer electron behavior. Those with 4 outer electrons (Group IV, including silicon, carbon, and germanium) contains what are called “elemental semiconductors,” which are materials with conductivity that lies somewhat between conductors and insulators. In general, a conductor has around 1 to 2 freely moving electrons per atom, semiconductors have 1 around freely moving electron per 10^7 to 10^17 atom.

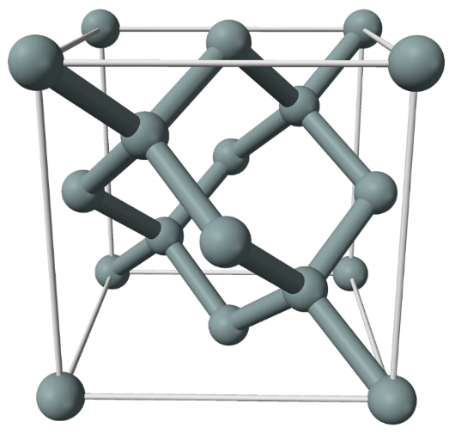
The outer shell for atoms in this (and most parts) of the periodic table try to grab 8 outer electrons (which is why the noble gases, with 8 outer electrons already, do not easily form compounds). Since each in Group IV comes with 4 already, they each want 4 more. Forming a crystal of carbon, silicon, or germanium causes the atoms to form a diamond cubic crystal lattice, in which each atom sits at the center of a tetrahedron, and connects to 4 neighbors. In this form, each atom has shares the 4 outer electrons with 4 neighbors, and each neighbor shares one back. Think of each atom as getting the desired 8 outer electrons part of the time, and sharing part of the time.
The lattice of silicon and some other group IV elements can be viewed as having atoms at each corner and face of a cube, with bonds shared as in the diagram. The electrons forming bonds pull the lattice together and the positive charges in the nucleus repel to hold the spacing apart.
As a simple example of a basic computation, look at one primitive cell of silicon (pictured). A good estimate of the side length of such a cube can be computed from knowing a few basic facts: the atomic weight of silicon is about 28, Avogadro’s number is 6.022×10^23, and the density is 2.3290 g/cm^3. Counting how many atoms exist in each primitive cell, each corner atom is shared by 8 cells, each face atom is shared by 2, so there are (8 corners/8 shared) + (6 faces/2 per face) + 4 interior = 1+3+4=8 atoms per primitive cell. Thus in 2.3290 grams of silicon there are 2.3290/(8*28/(6.022×10^23))= 6.26127*10^21 cells, which makes a cube with (6.26127*10^21)^(1/3)= 1.84312*10^7 cells per side, so each measures 1/1.84312*10^7 = 5.42558*10^-8 cm = 5.43 Angstroms per side.
Of these Group IV elements, silicon is used as the basis for modern semiconductors, because of multiple reasons: it forms high quality compounds like the insulator silicon dioxide (SiO2), it has a nice band gap (long story!) of 1.1 eV, making it perform well at room temperatures, it is cheap, and it is easy to build into low defect atomic structures.
Atoms from neighboring columns of the periodic table have either 3 or 5 outer shell electrons, and carefully mixing them in when making the silicon lattice results in a material with either more or fewer electrons than the eight per outer shell that pure silicon would give. These atoms take the place in the lattice of what would have otherwise been silicon.
Adding Group V phosphorus (P) adds one free electron per atom which can move much more freely than electrons in pure silicon, increasing conductivity. Adding Group III aluminum (Al) would result in one fewer electron per Al atom, and now instead of an excess electron, there is a shell missing an outer electron, which results in a pull on any electron to try and fill the shell.
Any resulting excess electrons move much more easily than the eight ones bound in cells, and any deficit of electrons results in ‘holes’, which are places an electron is pulled into the missing slot to fill an outer shell. In the theory of solids and semiconductors, these holes are treated as particles, since as electrons are pulled in, the ‘hole’ effectively moves around the lattice. So conceptually this hole is thought of as a moving positive charge, when in fact it is physically merely a pull on negative charges (electrons) to fill the hole.
Adding these electron rich or poor atoms to the silicon lattice is called doping, with the added elements called dopants. Boron, which has only three outer shell electrons, is the most widely used group III dopant, and resulting group III doped materials are called p-type materials, meaning they have excess positive charges (holes). Phosphorus and arsenic are the most widely used group IV dopants, and with 5 electrons in their outer shells, are called n-type dopants, since they have excess negative charges.
The result of careful adding of the right amount of the right kinds of atoms to the silicon crystal as it is formed can change the conductivity drastically. Substitution of just one dopant atom per 10^7 atoms of Si can increase the conductivity by a factor of 100,000.
Now I can explain how flash memory works.

Flash memory is made using individual physical “cells” to store logical values, with physical structure as in the diagram. The N and P materials are dopes silicon, and the insulator is usually silicon dioxide.
For current to flow from source to drain, it must pass through the n-type source, the p-type base, and then the n-type drain. At each n-type to p-type boundary, the holes in the p-type material attract electrons from the n-type, pulling them across, filling some of the holes. This creates a potential barrier, so a higher amount of voltage is required to get electrons to flow than if there was only one type of material.
Now, if the floating gate is has no net charge, and enough positive charge is applied to the control gate, then electrons are pulled from lower regions in the p-type material towards the control gate at the top, making more electrons available between the source and drain. This allows current to flow at a lower source to drain voltage, since there are more electrons in the conduction band along the top of the p-type material. Both the control and source to drain voltage are carefully measured.
If electrons are stored in the insulated floating gate, then the field from the positive charge on the control gate is somewhat hidden (or shielded, or cancelled out) by the electrons in the floating gate, and so fewer electrons get pulled into the into the conduction band in the p-type material below. The result is a higher voltage needs applied to the control gate to allow the same current to flow from the source to drain as before.
The lowest control gate voltage that allows a certain current to flow is measured, and the difference is used to differentiate between amounts of electrons in the floating gate.
In single level cells (SLC flash) the charge is treated as on or off. In multi-level cells (MLC) different amount of electrons are stored, representing multiple bits per cell, at the cost of being less robust, noisier, more prone to error, etc. For MLC the control gate voltage needs to be able to differentiate between more states in the floating gate.
In order to be erasable, writable, the floating gate needs to store electrons without applied power, thus needs to be insulated, and needs to have electrons added and removed to set the logical states.
The insulating layer is silicon dioxide, which has to a very precise thickness: lower thickness allows lower voltage operation, but also allows more leakage over time. It cannot be thinner than about 7nm if data retention of 10 years needed. Too thick and it’s slower and takes higher voltage to program the cell.
Programming is the act of placing electrons into the floating gate, and is often done by hot electron injection or sometimes by quantum tunneling (of a sub-type called Fowler-Nordheim tunneling).
In hot electron injection, a large enough voltage is formed from source to drain to cause electrons to accelerate from source to drain with enough energy to penetrate the insulating material. To get them to turn upwards and enter the floating gate, enough voltage is applied to the control gate to turn them. To get enough electrons into the floating gate in the programming time, the variations on voltages, materials, operating temperature, etc., all come into play. Lower current means less electrons generated and lower voltage means lower electron energy which both mean longer programming time. In general electron energy needs to be near 3eV, and it’s common to float the drain, place +6V on the control gate, and -5V on the source. These higher voltages are created on chip using voltage pumps.
In quantum tunneling, lower energy electrons are used, at the cost of slower programming time. A benefit is a decrease in physical damage over time to the materials. In practice both effects contribute.
Programming damages the insulator over time, electrons get trapped in the insulating material and nearby material, and the insulator is physical damage from being bombarded with high energy electrons, so over time breakdowns in the ability to add or remove or store electrons contribute to flash memory wearing out.
To erase the cell, the electrons need removed, and this is done almost exclusively by quantum tunneling, which is done by putting enough potential across the gate and base to allow the electrons in the insulated region to quantum tunnel out. Quantum tunneling is not like a classical tunnel being bored – it is more like a teleportation where the electron just “jumps” out. Quantum tunneling allows electrons to jump over energy barriers that a classical particle could not overcome, and the probability of how and where it jumps is related to the size of the energy barrier involved. By increasing the voltage across the gate and base, the energy barriers are effective lowered enough that the electrons have a large enough probability of jumping out that erasure occurs. However, when and where the electron jumps to is probabilistic, so there is some change it just jumps into the insulator. Similarly, excess electrons may tunnel out of the insulator, making the effect less damaging.
For SLC flash, when the memory is erased via quantum tunneling, the memory reports this as a logical ‘1’, and when the container holds enough electrons, the memory reports a logical ‘0’. This process is inherently slower than programming, which is why erasing flash is slower than writing. For MLC and TLC different electric field levels correspond to different bit patterns.
Finally, a final failure mode in flash is caused by electric charge in neighboring cells and nearby material causing the desired cell to read incorrectly due to those charges contributing to the electric field strength of nearby bits. As cells are made smaller and smaller, this becomes more of an issue.
Flash memory comes in two main types, NAND and NOR (named after some of the underlying gates), one difference being whether or not the memory allows random read accesses. NAND allows memory to be erased or written in blocks, while NOR allows single cells to be read. Since NOR requires more circuitry, it is more expensive per cell. As a result of NOR allowing individual cell access, most microcontrollers use NOR for storing execute-in-place code, since it is more efficient to execute code from memory allowing random access. NAND is cheaper, thus used for long term storage in many other devices like iPads and SSD drives.
NAND flash is accessed like block devices, each block consists of pages (sizes of 512, 2048, and 4096 are common). Reading and writing are page level, erasure is block level. To execute code form NAND, it is usually copied to RAM first, using some form of memory management unit. Additional bytes add error correction to increase reliability and lifetime, and many devices have sophisticated memory controllers that perform wear leveling to increase lifetime. Microcontrollers rarely have this level of support for the flash in them.
Both NAND and NOR erase a page at a time (or sometimes more).
Finally, Wikipedia lists common write endurance of
Here is the experiment we did on an actual device to see how flash degrades. The microcontroller we used is a PIC32MX150F128B [PIC150], mostly because we already had many nicely hackable boards we developed using this PIC in the form of our HypnoLSD modules (LED strand controllers, pictured). This PIC has 32K of RAM and we ran it at 48MHZ with a 1Mbaud serial connection to output logging data. We ran 1 million erase/write cycles on a device rated for 20,000 erase/write cycles.

This PIC has 128K of NOR flash and an additional 3K of flash for a boot loader. The flash page size is 1024 bytes, row size is 128 bytes, and the flash is addressable as 32-bit words. The hardware has support for
Even though the smallest possible writeable section of flash is a 32-bit word, before we undertook this experiment (and I learned details on how flash worked), I noticed erasing flash sets all bits to 1, and I could progressively write 0 bits to any location by properly reading a word, setting the proper bits, and writing the word back. This allowed storing the changes I needed in smaller portions of flash by incrementally setting fields.
For an idea of what this flash looks like on a die, [siliconporn] has a die shot of a related PIC device, the PIC32MX340F512H (512K flash, 32K RAM), which has a bit cell pitch of 1015×676 nm (which is 0.686 μm^2/bit); I suspect the PIC we tested is made with similar size gates. I could not find a die shot of our particular PIC.

Based on how bits fail from the above details on how flash works, I expected once a bit failed it would later work again, then fail again, etc. Thus I only wanted to log changes between failing and succeeding in order to lessen the amount of messages logged. To track these changes I needed RAM buffers to compare last state and new state for each bit tested in flash for both the last erased result and the last written result, requiring 2 bytes of RAM for each 1 byte of flash tested. Since some RAM was used for variables, I chose to use 4K of RAM for testing 2K of flash at a time, with 8 such regions testable, selectable while running.
This allowed testing two flash pages (256 words = 1024 bytes each) at a time.
The code on the PIC is a small C application that sets up the hardware, then loops over erase/write cycles, writing any failures to the output serial port. I logged the output to a file, which took around 34 hours to log 1,000,000 erase/write cycles. Later cycles got much slower as more errors were reported. If I run this again, I’ll set the logging speed to 3 or even 12 Mbps to speed up the overall process. The code for the PIC portion is at https://github.com/ChrisAtHypnocube/FlashWrecker.
In slightly more detail, the code loops over the following:
The resulting log file is 4.6GB of text which has the form:
...
Pass 723466, frame 0, offset 00000000, time 908b5feb, errors 824483
ERROR: (E) offset 0000001E read FFFFFFFB desired FFFFFF7B.
ERROR: (E) offset 00000046 read FFFFFFFF desired 7FFFFFFF.
ERROR: (E) offset 00000084 read EFFFFFFF desired FFFFFFFF.
ERROR: (E) offset 0000008E read FFEFFFFF desired FFFFFFFF.
ERROR: (E) offset 000000B7 read FFFFFFDF desired FFFFFFFF.
ERROR: (E) offset 000000C4 read FFFBFFFF desired FFFFFFFF.
ERROR: (E) offset 000001B8 read FF7FFFFF desired 7F7FFFFF.
ERROR: (E) offset 000001BE read 7FFFFFFF desired FFFFFFFF.
ERROR: (E) offset 000001D2 read FFFFFF7F desired FFFFFFFF.
Pass 723467, frame 0, offset 00000000, time 90aea31f, errors 824492
ERROR: (E) offset 00000046 read 7FFFFFFF desired FFFFFFFF.
...
The logs contain an erase/write pass number, the memory offset into my reserved flash region (frame is 0-7 to select different parts of the region to test), a time in the form of an internal 32-bit CPU core tick, and the number of errors so far detected (technically, these are both errors and later corrections when that failed bit works again, so it is roughly a double count of bit failures).
For each pass, each word is checked against what it should be, as recorded by what it was last time the state was attempted on that flash word. A memory offset is output, what was read at that location, and what was recorded in RAM as the last read value from that location. Then the RAM is updated, and the cycle continues. The error type (E) or (W) denotes an error in the erase or write phase.
Logging was done by adding file logging support for our Hypnocube device controller (https://github.com/ChrisAtHypnocube/HypnoController), which allowed me to quickly develop a method to run the experiment. Any decent logging serial terminal would do as well, but I wanted to make sure it supported huge files, used different threads for reading and writing to avoid missing any inputs at high speeds, and flushed messages to the file properly in case of something crashing. Writing my own logging based on our existing code ensured these goals were met.
After a few initial passes on a first device to get all related software parts working, we programmed a new PIC and started recording output. One and a half days later we reached 1.1 million passes, with over 40 million bit errors, and decided to stop and analyze the data.
To analyze the data, I made a second C#/WPF program (at https://github.com/ChrisAtHypnocube/FlashWreckAnalyzer) that reads in the log file, allows interactive visualization of the time changes of the flash, computes some stats, and ultimately creates a visualization of the flash degradation.
The main thing I wanted to test is the accuracy of the statement: “each bit is independently likely to fail, with exponential dependence on number of erase/write cycles”.
A final visualization of the million frame degradation is at https://www.youtube.com/watch?v=7elfyRyW5ms . Here is the final frame of the visualization:
In the picture (and animation) bits are laid out 32 to a word, 4 words to a row, and 64 rows to a flash page. The erase/write cycle just ended is listed in large letters.
On the right are two bars that move up during the animation: the left blue one is the frame, and the right one stays at the same height showing an error graph, with width from 0 to the max number of errors detected.
White/gray bits have not failed, light red bits have failed on an erase and remain failed, light blue bits have failed previously but erased on the last attempt, and the richer/bigger red and blue bits have done the same but exactly on this cycle. We had no write failures, so I did not put colors for them in the legend, but they are in the code.
Below are some other stats, like elapsed time, and some other stats, explained below.
First failed bit happened on cycle 229,038 at bit index 8207. A separate run on a separate device had a first bit failure around cycle 400,000. So (given the small sample size of 2!) it appears that 20,000 cycles is quite conservative. I could not find a detailed description of how Microchip arrived at their value; perhaps it was an earlier manufacturing process, and the data sheets are out of date.
The first thing we noticed from the image above is that the failed bits seem to prefer certain horizontal regions. To look for other patterns, I gathered lots of stats on the failed bit patterns.
Some are shown on the screen; here are descriptions and comments. For each value of N in 0, 1, …, 31, I recorded
Besides these stats shown on the visualization, other stats were computed and saved at the end. Here are graphs and commentary. Each is described as y-axis value versus x-axis value.
#2 from above should be nearly a straight line; instead we get this plot of number of bit errors versus bit index in a word of 0, 1, …, 31. A distribution this skewed is very unlikely.
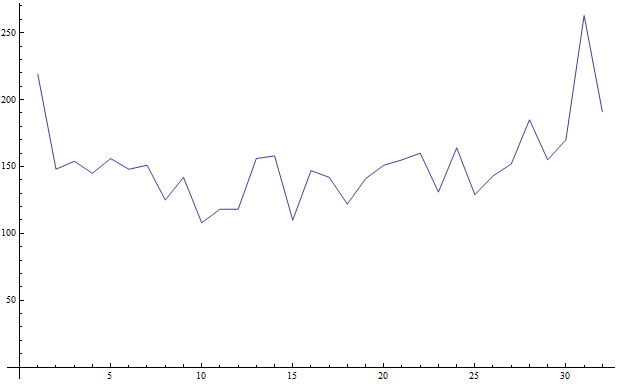
Plot of cycle where a new bit failed versus bit failed count (4857 total failed bits). This graph is what I would expect.

Gaps between successive new bit failures versus bit failure count. Again, nicely spread.
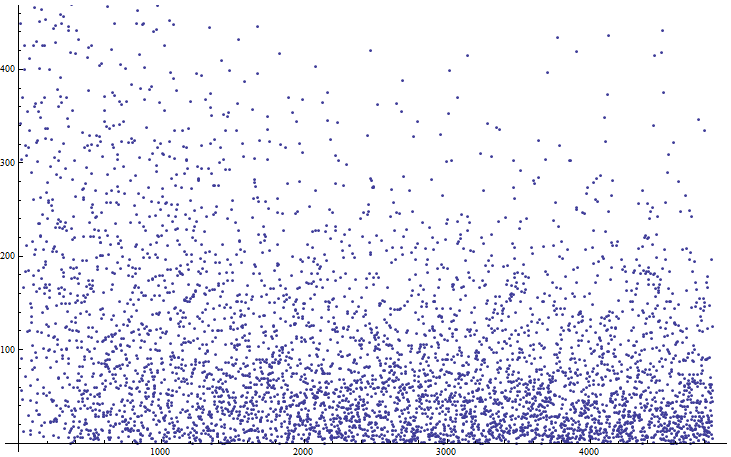
Bit position 0-16385 versus order the bits failed. Here you start to notice banding in 4 strips….

The above (and the visualization) lead to inspecting the number of failures per row (a row in the PIC is 128 bytes). The number of failures per row is 428,432,170,157,477,474,151,166,390,384,172,183,480,471,163,159. This is a graph of failures per row versus row 0-15:

This clearly looks like some underlying factor is biasing the failures. A quick estimate to check how likely this could happen randomly gives: there were 4857 failed bits out of 16384 monitored, if we assume bits are equally to fail, we can ask the question: what is the probability eight rows have a total at most 183, and eight rows have a total at least 384. The probability of this happening if bits are uniformly likely to fail is less than one in 10^-134, so not likely. This is a clear bias.
Once a bit failed, it usually started working again, then failed again, then worked again, etc… I would expect that the lengths of the working state would decrease, and the lengths of the failed state would increase. To check this for one bit, I took the first bit to fail (since it recorded a lot of success/fail transitions), and computed all the lengths of each mode. There were 7293 intervals where the bit as failing, and 7293 regions where the bit was working (after the first fail). The result is very noisy, making it hard to visualize. However, taking moving averages over 1000 samples at a time results in the following:
Moving average length of intervals where first bit is working versus sample index (moving average over 1000 samples):

As expected, the success interval length decreases over time, but is not very smoothly doing so.
Doing the same for the failed interval lengths: moving average length of intervals where first bit is failing versus sample index (moving average over 1000 samples):

This somewhat increased, but again is very messy. I’m not sure how to interpret these two graphs nor what to do to refine my knowledge.
A similar stat is gathering all runs from all bits, and counting how many times each length occurs, and plotting them.
Lengths of successful run intervals, showing the first 80K out of 107097 entries, using a moving average of 1000 entries, versus length

Lengths of failed run intervals, showing the first 80K out of 107097 entries, using a moving average of 1000 entries, versus length

These show that long runs where a bit has failed are not as likely as short runs, with the decrease fairly well behaved. The runs for the successful are not as well behaved, but they too decrease with length.
A final interesting point is we noticed no failures to write a bit, only failures to erase a bit.
Conclusions, things to do in the future, and other final points
8) It would be interesting to search the data for other types of bias, and to get a good die shot of the PIC, and figure out what causes the biases we found.
Finally, since the errors in this flash are pretty well spread over random bits, and not in bursts (except for the row bias), BCH codes are a better choice for error correction in these devices.
[HypnoLSD] http://hypnocube.com/products/controllers/hypnolsd/
[siliconporn] http://siliconpr0n.org/archive/doku.php?id=azonenberg:microchip:pic32mx340f512h
[video1] https://www.youtube.com/watch?v=7elfyRyW5ms
[PIC150] http://www.microchip.com/wwwproducts/Devices.aspx?product=PIC32MX150F128B
The World Maker Faire in New York City is this weekend and we’ll be there for the second year! We’re (almost certainly) going to be in the Viscusi Gallery, upstairs inside the New York Hall of Science building. Come say hi and check out what we’re working on!
![]()
This post wraps up one remaining issue from Part I (http://hypnocube.com/2013/12/design-and-implementation-of-serial-led-gadgets/), namely, figuring out how to control long strands of WS2812 LEDs, which fail above certain lengths due to timing skew.
The last post detailed our findings on how the internals of the WS2812 chip likely work, and resulted in detailed knowledge of how the signal timings must be shaped to get the LEDs to transition correctly. From this we implemented the ability to tweak timings in our code for the various components of the signal, and we experimented with long strands to see how far we could reliably get a signal to propagate.
Our testing rig was composed of eight strips of 1250 LEDs each, for a total of 10,000 LEDs, the maximum our controller will run. We built these into circular arc panels, which allow us to stack them in various configurations. Here is a YouTube video showing the resulting panels playing animations.
Due to the circular sides you can only see 6 of the 8 panels at once. Our testing involved using all eight panels in various configurations.
From last time, we created a controller, the Hypnocube LED Serial Driver (HypnoLSD, http://hypnocube.com/product/led_serial_driver/), that executes 60 instructions in 1250ns (a PIC32 clocked at 48Mhz), which is the recommended timing length for one bit of data sent to the WS2812 modules. Figure 1 shows the timing diagram from last time.

Figure 1- Timing Labels
From experiments last time, we decided that making the final low signal longer does not cause errors, allowing us to change the length from the usual 1/3 of the window to many multiples of this. Changing the required high and middle parts did not help us control errors. When we tried to run strands over about 5,000 in length, there was significant data corruption, and we could not get images on long designs. The issue was bit transitions stacking up too tightly due to the WS2812 signal shaping causing skew, and eventually a transition is either lost or pushed into a time window where it was ignored. So we wanted to introduce longer timing windows to see what happened.
Due to the density of our code, we initially tried changing only the delay at the end of each byte sent, but this resulted in no real error reduction. Next we implemented per-bit user selectable timing, and this resulted in the ability to handle long strands.
Initial testing showed some variation depending on what we tried to draw, so we picked simple colors with various bit-transition patterns to help us understand what is happening. For example, trying to go from an all-white image to all red behaved differently than going from all black to all red. Likely the timing skew introduced by the modules is somewhat power dependent. So our initial experiments went from an all-black image to a solid color.
In the following, the “bit-delay” is one-half of the number of instructions we increase the low part of the timing diagram (the ‘w’ in Figure 1). Due to the existing code density to handle the throughput, we could only squeeze in a few instructions per bit, resulting in timing loops illustrated in Figure 2, where the “bne” instruction loops back to itself, while decrementing the counter in the following branch-delay slot (this is an artifact of MIPS assembly – it looks odd at first to the uninitiated, but is correct).

Figure 2-PIC Assembly timing loop
As a result, since each instruction adds 1250/60 ns to the time, each increase in bit-delay adds 1250/30 ns (41 and 2/3 ns) to the initial 416 + 2/3 ns value of ‘w’. Each experiment is repeated 10 times for various bit-delays, and the number of panels out of 8 that show correct results is recorded. Thus a score of 8 means all 10,000 LEDs were correctly set. For each experiment, the LEDs are set to black (color 0, 0, 0 – all off), and then an image is sent down them.
Note longer bit-delays result in longer transmission times, lowering effective frame rate. Since the initial window is 60 instructions for a bit, and each increase in bit-delay adds two instructions, each increase in bit-delay increases time per bit by one part in 30.
We set up all eight panels in serial as one long 10,000 LED strand, used a 3Mbps serial connection to our gadget (which may be immaterial), and sent the GRB byte colors 255, 0, 170 (to get many bit transitions) down the strand.
Here are the results:
| Bit-delay | # panels perfect out of 8, for 10 experiments | |||||||||
| 0 | 5 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 4 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 |
| 6 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 |
So in this experiment, a bit delay of 6 allowed us to transition all 10,000 LEDs from black to the selected color, while the default timing allowed only about half that many to be changed.
Next we sent the GRB color 128, 0, 1, for another ten experiments on the 10,000 LED strand, resulting in
| Bit-delay | # panels perfect out of 8, for 10 experiments | |||||||||
| 0 | 3 | 4 | 4 | 3 | 3 | 3 | 3 | 4 | 3 | 4 |
| 1 | 5 | 4 | 4 | 5 | 4 | 4 | 5 | 4 | 5 | 4 |
| 2 | 5 | 5 | 5 | 6 | 5 | 5 | 5 | 6 | 5 | 5 |
| 3 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| 4 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 |
| 5 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 |
| 6 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 |
This time a bit delay of 4 was sufficient, which failed in experiment #1. A bit-delay of 6 still worked. Note this transition drew a lot less current than the last one.
Repeating with the GRB color 1, 2, 3 on the 10,000 LED strand resulted in
| Bit-delay | # panels perfect out of 8, for 10 experiments | |||||||||
| 3 | 5 | 5 | 5 | 5 | 5 | 6 | 6 | 5 | 5 | 5 |
| 4 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 |
Again, a bit-delay of 4 was enough, but the bit-delay 3 showed slightly better behavior than the previous tests. Note again the lower color numbers draw significantly less current.
Out of curiosity, we wanted to see how large we could make the bit delay, and obtained, for color 128, 0, 1, on the 10,000 LED strand,
| Bit-delay | # panels perfect out of 8, for 10 experiments | Notes | |||||||||
| 16 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | |
| 32 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | |
| 64 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | |
| 96 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | |
| 98 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | |
| 99 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | |
| 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 104 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 112 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 128 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | (1) |
| 136 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | (2) |
| 144 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | (3) |
| 160 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | (4) |
| 192 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | (4) |
| 256 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | (4) |
Notes:
(1) Many pixels change, very noisy.
(2) About 600 or so pixels change
(3) About 1 or 2 pixels flicker, perhaps hitting latches?
(4) no pixels change
We found a bit delay over 100 completely dropped the signal, a cutoff that was observed in others (non-recorded) testing. This results in a 5000ns bit period, which, oddly enough, is not near the approximate 9400ns latching requirement we deduced last time. However it is four times the recommended bit-length.
We initially thought that no larger bit-delay would reverse this behavior, but upon trying some larger values we got noise on the panels. The noisy LEDs seem to be dropping an entire byte at a time, leading us to speculate there are 3 independent counters in chip, triggering some weirdness between them. We also tested holding the last signal high a long time, instead of the low required to latch colors, and this led to more interesting noise. But we did not pursue it much due to the apparent complexity of the outcomes.
We then performed testing over the animations shown in the video linked above. There are about 30 or so animations we wrote in our custom software, with no special regard to overall brightness or pixel coverage. Since the previous experiments suggested a bit-delay around 6-10 resulted in stable images, we tested it. The results were a bit odd.
Testing with the panels arranged as a 10,000 LED strand resulted in most demos working, with the one we call “Fire” by far the most noisy. Under visual inspection it did not appear any more or less complex than the ones we call “Plasma”, but mathematically it would have somewhat more “randomness” between adjacent pixels. We found
| bit delay | Notes |
| 8 | fire flakey on 8th panel |
| 16 | fire flakey on 8th panel, better than bit-delay 8 |
| 32 | fire flakey on 8th panel, better than bit-delay 16 |
| 64 | fire flakey on 8th panel, almost fine, boundary seems to be noisy |
| 99 | fire fine |
We suspect there are soldering issues between panels that is adding to the noise, which is why it took such a high bit-delay to get the “fire” animation to work, when all the other ones ran fine.
Rewiring the modules into a two 5,000 length LED strands led to the following:
At bit-delay 2, all demos except “Fire,” “Plasma,” and “Ray tracer” worked fine. At bit-delay 4, “Ray tracer” went to mostly fixed. At bit-delay 20, all were better, but still a little flakey. We suspected some bad wiring was making noise. At bit-delay 4, with fire drawing upside down, it worked fine, leading us to suspect wiring or a flakey LED.
We did find flakey LEDs in the middle of a strand several times, where the signal suddenly went bad. Replacing them fixed several issues.
Running the GRB color 128, 0, 1 similar to experiment #2 except on the two by 5,000 LED arrangement led to the following:
| Bit-delay | # panels perfect out of 8, for 10 experiments | |||||||||
| 0 | 6 | 7 | 6 | 7 | 7 | 7 | 7 | 7 | 6 | 6 |
| 1 | 8 | 7 | 8 | 7 | 8 | 8 | 7 | 8 | 8 | 8 |
| 2 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 |
Experiment #2 required a bit-delay of 4 to get 10,000 LEDs working correctly; this experiment required a bit-delay of 2 to get the 2 x 5000 configuration working, with a bit-delay of 1 almost sufficient.
Testing the panels as four by 2,500 strands, with a bit-delay of 0 (the default, spec recommended value), resulted in no errors on our demo animations.
Frames per second maxed out around 8.5 fps, which was limited by the 3 Mbps serial input. We tested at 12 Mbps and it worked fine.
Running the panels as eight length 1250 panels worked flawlessly with bit-delay 0 at both 3Mbps and 12Mbps inputs.
From our experiments, it seems the default WS2812 protocol can easily handle 2500 length strands, and with careful wiring probably even 5,000 or so. We were not terribly careful in our designs, but we would be surprised if 10,000 LEDs could be controlled reliably at the specification recommended timings. If you find out otherwise, please let us know.
We noted there seemed to be increased noise at solder junctions (as expected), or other non-homogeneous parts of a design. For example, if you have a long strand, then some wiring to get to your next strand, there is the possibility of this in-between wiring introducing noise.
As a result of these experiments, we added the ability for end-users to select the bit-delay in our modules in order to see what works for their designs. We found that bit-delays of around 200-400ns on the low portion of the per-bit signal adds significant reliability for long strands.
Since we did this work we have built several LED gadgets and displays based on our modules, and have sent samples to several others. So far they seem to work just fine. Let us know if you find otherwise.
Happy hacking!
We’re going to be at the Detroit Maker Faire this weekend! Come by, say hi, and see what we’ve been up to. I’m not sure where our booth is located yet, but it will be somewhere indoors (last year they had us in the back in a slightly darker area with other lights projects.)

We made a video of the 10K LED test rig for the HypnoLSD module!
(Click through to YouTube for HD version)
We’ll upgrade any domestic US order made between now and ThursdayFriday to 2nd day shipping, free! Just order as usual and I’ll make sure it goes out 2-day.
(Did I say Thursday? I meant Friday. For some reason I thought Christmas was on Tuesday.)
By Chris Lomont, Nov 2013
(See part II at http://hypnocube.com/2014/07/design-and-implementation-of-serial-led-gadgets-part-ii/)
Gene Foulk and I obtained a batch of WS2812 LED strips a few months ago, and wanted to play with them, but their unique timing protocol made it somewhat of a hassle. We wanted to drive large numbers of LEDs (on the order of 10,000), and many of the open source libraries would make the driving hardware messy and/or expensive, so we decided to look at what we could create that would allow easy control of large numbers of LEDs at fast frame rates. We decided on making a driver module that was the blend of powerful and cheap that suited our purposes. The result is our upcoming HypnoLSD module.
This article is a summary of some things we did and learned about WS2812 LED strips that should make your designs easier to complete.

The popular WS2812 LED strips take the WS2811 LED driver and place them into a 5050 sized (5×5 mm) RGB LED module to create a tiny, serial driven 24-bit LED module. They are cheap (around $0.15 or less per module), readily available [Alibaba], and most of all, make neat gadgets.
There are quite a few similar chips and systems similar to the WS2811/WS2812/WS2812B. Some are interesting because they are predecessors from the same company and imply design information useful for understanding features needed for large scale construction.
Here is a summary of some other devices. We have not worked with them, so this is sourced from various datasheets and comments found on the internet.
Titanmech makes the TM1804 [TM1804] and TM1809 [TM1809], driving 3 and 9 channels respectively. They operate at 6-24V, have a 1800 nanosecond (ns throughout) bit-length, and seem to use a protocol similar to the WS2811, but may be SPI. There are also TM1803 and TM1812 modules which we did not look up yet.
LPD8803, LPD8806, LD8809, and LPD8812 are LED drivers that run 3, 6, 9, and 12 LED channels respectively, so can drive 1, 2, 3, or 4 RGB LEDs per module. They also claim a built in 1.2MHz oscillation circuit, use a 2-wire input control up to 20MHz, do 24-bit color, and support voltage up to 12V. They claim support for over 2000 length cascades.
Worldsemi [Semi] makes several LED driving chips and modules, including the WS2812 which we are investigating.
The WS2801 uses a SPI input up to 25 MHz, does three channel 8-bit output (i.e., 24-bit color), and interestingly states it also has an internal 1.2 MHz oscillator, giving a refresh rate approximating 2.5 kHz. It runs on a 3.3-5.5V power supply, provides 200mA per (three?) LEDs, and has signal shaping. Note that 1.2MHz/(256*2) is almost 2.5kHz, so it’s reasonable to think this 1.2MHz counter drives a counter that turns on/off the LED for PWM. We think this is how the WS2811/WS2812 operates.
The WS2803 also has an SPI input up to 25MHZ input, does 18 channels (6 RGB LEDs worth), 8 bit output per channel, refresh rate approximately 2.5 kHz (implying another 1.2 MHz internal oscillator?), operates on 3.3-5.5V supply voltage, has PWM output (and also says 18-bit constant current output?), has signal shaping, drives 30mA per channel, and has built-in over-temperature protection (the LED shuts off).
For completeness, and to transition to our needs, the WS2811 claims a non-return-to-zero (NRZ) input (but it seems to be a return to zero in my opinion) at 400kbps or 800 kbps, 24-bit output (8 bits on each of on three channels), has an “internal precision oscillator” and refresh rate approximately of 2.5 kHz (implying the same internal 1.2 MHz oscillator?) , a 5-12V supply voltage, PWM output, signal shaping, drives 30mA per channel, and has an on chip regulator.
Adafruit [Adafruit] has open source libraries to drive various chips from various microcontrollers. Look around at their site to find them.
The Worldsemi WS2811 chip is a LED driver, upon which the WS2812 added a LED module. The WS2812 is a 6 pin chip running on 6-7V. The WS2812B [WS2812B] is a modification of the WS2812, giving a newer 4 pin version (Vss, Vdd, Data In, Data Out) that runs on 3.5-5.3V. The marketing claims he WS2812B “inherited all the good qualities of the WS2812,” improved the IC mechanical arrangement outside to the structure inside, and further enhanced the stability and efficiency. It claims better, brighter color, and more uniform color. One good improvement is making reverse power connection not damaging the device. [WS2812+WS2812B]
These format devices, using a 2-wire protocol, have no timing line, thus end up being cheaper at the downside of using a weird timing protocol. Some microcontrollers use SPI at 4MHz with tricks to write to these devices, by banding bits together to make long and short high pulses.
All support a wide range of operating temperatures, with junction temperature ranges listed as -25 to 80 degrees Celsius.
Most of what follows is both for the WS2811, WS2812, and WS2812B, except where marked.
The WS2811/WS2182/WS2812B modules are driven by a single data line, with the chips connected in series; the Data Out pin of one is connected to the Data In of the next. Color information is sent to the first in the chain, one bit at a time. Each module “absorbs” 24 bits of color information to drive three output LEDs, usually red, green, and blue (but could support whatever someone makes), then succeeding bits are passed on down the chain for subsequent modules to use. In this manner 24 bits can be sent to each LED module in the chain. A final low signal, held long enough, signals all modules to latch the color data to LEDs, using pulse width modulation (PWM) to hold that color until a new set of colors is loaded and latched.
Bits are modulated in the following manner: the input line starts low (0 volts, say), and toggles high (5V, say), signaling the start of a bit. These voltages depend on the reference voltage powering the module, and we have found them somewhat tricky if you do not follow the specs carefully. This line is held high either a short time T0H (marking a 0 bit to be transferred) or a longer time T1H (marking a 1 bit to be transferred), then dropped low again. This process repeats, sending all bits. Each bit has the same length overall. The time between low-to-high transitions determines the bit rate.
This timing is captured in the following figure:

The supported data rates are 800 kilobits per second (kbps) or 400 kbps, meaning each bit length is 1250 ns or 2500 ns, respectively. For the rest of this document we’re only going to discuss the 800kbps rate because it allows the most LEDs in a single strand to be driven at a high frame rate, and is what we investigated and implemented.
The timing rates for the internal high and low timing lengths, and the longer reset timing signaling a latch, are listed at various places with different values, sometimes self-contradictory. Our testing shows quite a range is possible, which we detail below. Most places list the overall bit length as 1250ns (which is 1/800K) and the timing error to be plus or minus 600ns (giving rates from 540kbps to 1.5Mbps), and each of the four timing components to be plus or minus 150ns. Since each bit only uses two of the four timing components, this doesn’t add up. I suspect someone saw the four timing numbers, each allowing error of 150ns, multiplied by 4, and thought the overall timing can be off by 600ns. Using a more likely overall error of plus or minus 300ns, the bit rates will be in 645kbps to 1Mbps. We have found longer times work fine, but no LEDs worked at a 650ns rate. Next, timings in some datasheets don’t add up to the overall listed bit length. As a result, we tested quite a lot of timing scenarios, and find the timing can be pretty sloppy and still work (until you start dealing with lots of LEDs. More on that later.) For most of our development we chose to break the overall interval into thirds, partly because it made the timing easier to put cleanly into code. For the table, we put all times in nanoseconds to show that the reset is on the order of 40 bits worth of time. In practice this can be much shorter.
| Source | TH+TL | T0H | T0L | T1H | T1L | Treset |
| WS2811 data sheet [WS2811] | 1250ns | 250ns | 1000ns | 600ns | 650ns | 50,000ns |
| WS2812 data sheet [WS2812] | 1250ns | 350ns | 800ns | 700ns | 600ns | 50,000ns |
| WS2812B data sheet [WS2812B] | 1250ns | 400ns | 850ns | 800ns | 45ns | 50,000ns |
| www.aliexpress.com | 1250ns | 350ns | 800ns | 700ns | 600ns | 50,000ns |
| www.doityourselfchristmas.com | 1250ns | 250ns | 1000ns | 1000ns | 250ns | 50,000ns |
| www.sparkfun.com [SparkFun] | 1250ns | 350 | 800ns | 700ns | 600ns | 50,000ns |
As the signal travels from one module to the next it is modified by the signal shaping. The WS2812 datasheet states “Built-in signal reshaping circuit, after wave reshaping to the next driver, ensure wave-form distortion not accumulate.” This, coupled with variability in module performance, has implications for large designs. It turns out that the signal shaping causes bits to be dropped for large designs. We will spend a lot of time below analyzing signal shaping.
Although the datasheet of the WS2811 shows data being sent in red, green, then blue order (RGB order), all WS2812 strips we’ve seen have the LEDs attached such that data must be sent in green, then red, then blue (GRB) order. Each color byte is sent most significant bit first, i.e., left to right:

Even though the WS2812B marketing material claims them to be brighter than the WS2812, the higher operating voltage of the WS2812 allows brighter LEDs, which is supported by the datasheets themselves. Here is color frequency, brightness, current, and voltage for each LED color.
| Red nm | Green nm | Blue nm | Red mcd | Green mcd | Blue mcd | current | Rv | Gv | Bv | |
| WS2812 | 620-630 | 515-530 | 465-475 | 550-700 | 1100-1400 | 200-400 | 20mv | 1.8-2.2 | 3.0-3.2 | 3.2-3.4 |
| WS2812B | 620-625 | 522-525 | 465-467 | 390-420 | 660-720 | 180-200 | 2.0-2.2 | 3.0-3.4 | 3.0-3.4 |
To gamma correct from the input number 0-255 to the output perceived brightness, one person [Gamma] empirically found this relation: outputValue = 255.0*(inputValue/255.0)^(1.0/0.45).
For simple use, buy a strip of around 100 LEDs, hook up a good 5V power supply, attach a ground and data line to your chip, and bang away. There are many libraries for popular chips so you won’t have to do much work. [PJRC] has some detailed information on a lot of WS2811 related topics.
We wanted to drive as many WS2812 LEDs as possible for a reasonable cost. Initial estimates led us to believe we could run 10,000 LEDs on a low cost PIC32 microcontroller.
We wanted to drive a lot of them at decent frame rates (at least 30 frames per second), so we focused on the 800kbps module version. At this rate, each bit uses 1/800000 = 1250 ns to transmit. A low signal of 50us, which is about 40 bits of timing, is used to signal the end of the image, at which point all the LEDs latch the image to their outputs. Each LED uses 24 bits to set its own color, then passes successive bit signals down the line. Thus a single strand running at 30 frames per second has maximum length of N=1109 LEDs. (Solve 30*(1250*24*N + 50000)=10^9).
So to run more LEDs, we need more strands; we need more output pins to output in parallel. To get 10000 LEDs running at 30+ fps, we need 10 pins.
To drive 10000 LEDs at 30+ fps, we need an input bit rate of at least 10000*3*30*8=7.2 megabits (Mbps)=240,000 bytes/second. USB, serial, SPI, and I2C are all common protocols able to supply this rate.
We wanted the device to be easy to use, and usable from low power devices and low speed microcontrollers, so we decided that a simple byte input format with a simple protocol would be best. If we had decided that the input should be carefully packed in weird formats on the user side, we could have slightly reduced the final requirements, but we opted against this on usability requirements. We also wanted some control protocols and other niceties to support robust testing, performance, and customizability for end users, all of which made the protocol slightly more complex. So we wanted a simple image input format of RGB tuples that could be generated on the fly by users. That meant our device would take this input, lay it out in RAM as needed, and play it back on the output pins.
We need to input and output 240000 bytes per second, so we must move 480,000 bytes per second. To get decent fps output, we need to stream the data across many pins, and the fastest way to do this is to split the bits needing output into streams. We wanted to output multiple pins worth of data with one write to a hardware port, and this data needed bits from multiple color bytes, so some bit fiddling needed done, packing (as it turned out) 16 bits from different input bytes per write.
So we have the minimum requirements
After evaluating several microcontrollers, we decided to use a PIC32 150F128B, which is a 32 bit processor, MIPS 32 core, up to 50MHz clock. Since USB and serial both had better supporting external hardware interfaces at a 48 MHz internal clock, we settled on that clock speed. We needed an external crystal for stability.
From past work on USB, we knew the USB stack would take too much CPU time, so we decided against on chip USB. Since UART is more common than SPI or I2C, very easy to work with, and there are nice USB to UART bridge chips, we decided on a serial solution. This way small microcontrollers could use serial to communicate with the device, and a PC could use USB to UART bridges. FTDI has a powerful 12 Mbps USB to serial chip (the FT232H) as well as lower cost 3Mbaud versions (such as the FT232R) [FTDI]. We have tested both extensively. Having never worked with serial at this speed (12Mbaud before), we found it amazing robust, not dropping even a single bit over hundreds of gigabytes tested, even using haphazard wiring.
Using serial, at 12Mbaud serial, with 8N1 signaling, it takes 10 baud to transmit a byte, so we can move 1.2M bytes per second, which is 9.6Mbps, enough to meet our 7.2Mbps requirement.
The PIC has 28 pins, and laying out how they are used to maximize features is always one of the fun parts of design like this.
From the design, we needed at least 10 general purpose input/output (GPIO) pins for output. On the PIC we chose one of the 16-bit ports (pins RB0-RB15) for output, so we could output on all 16 pins in parallel with a single CPU instruction.
To keep the timing stable, for both the LED output and the serial input, we needed an external crystal. This took two pins, which overlap GPIO pins RA2 and RA3.
For data input, we chose the UART1 port, which used GPIO pins RA0 and RA4.
For programming during development, there are three sets of programmer pins, all of which overlap with our output pins RB0-RB15. To make things as easy to use as possible, we chose the only pair not on the lower byte (RB0-RB7) of output, that is, the PGED/PGEC pair on RB10 and RB11. The programmer also requires the MCLR pin and Vdd and Vss.
After adding the final power and ground signals, the chip has precisely one unused pin, RA1, which we put to dual purpose for a flash settings reset on boot and for a LED for messaging during deployment.

This pin selection allowed us to use SPI on pins RB11, RB13, and RB15 for a second SD card driven version that has 8 output pins instead of 16.
Getting the software to handle the design requirements on such a low end microcontroller was the hardest task.
We wanted to allow users to have designs of 1-16 strands of LEDs, and for each we wanted to use RAM as efficiently as possible.
For example, using 16 strands, we can output one 16-bit word on the port at a time, and the 30,000 byte RAM buffer is treated as a 625 word tall buffer of 16-bit words. This allows 10,000 LEDs.
We also wanted to be able to do input and output continuously into the same buffer to maximize throughput. Alternating them would slow down the process, since writing to LEDs is slow yet must happen at very precise intervals.
To illustrate, consider a 3 strand design. Then we output 3 bits at a time, and we treat RAM as a 625 tall buffer again, where bits 0-2 are the 3 strands, then we return to buffer top and do bits 3-5, then bits 6-8, etc., until the last pass uses bits 12-14. This allows 5 passes through the 625 tall buffer, giving 5*625=3125 long logical strands. The last bit in each word, bit 15, is unused, resulting in some unused space, but packing more strands into that last bit would make the code even messier than it turned out to be. The resulting usable space is as follows:
| strands | max height | pixels | used bytes | unused bytes | % used |
| 1 | 10000 | 10000 | 30000 | 0 | 100.00 |
| 2 | 5000 | 10000 | 30000 | 0 | 100.00 |
| 3 | 3125 | 9375 | 28125 | 1875 | 93.75 |
| 4 | 2500 | 10000 | 30000 | 0 | 100.00 |
| 5 | 1875 | 9375 | 28125 | 1875 | 93.75 |
| 6 | 1250 | 7500 | 22500 | 7500 | 75.00 |
| 7 | 1250 | 8750 | 26250 | 3750 | 87.50 |
| 8 | 1250 | 10000 | 30000 | 0 | 100.00 |
| 9 | 625 | 5625 | 16875 | 13125 | 56.25 |
| 10 | 625 | 6250 | 18750 | 11250 | 62.50 |
| 11 | 625 | 6875 | 20625 | 9375 | 68.75 |
| 12 | 625 | 7500 | 22500 | 7500 | 75.00 |
| 13 | 625 | 8125 | 24375 | 5625 | 81.25 |
| 14 | 625 | 8750 | 26250 | 3750 | 87.50 |
| 15 | 625 | 9375 | 28125 | 1875 | 93.75 |
| 16 | 625 | 10000 | 30000 | 0 | 100.00 |
The MIPS core has 32 registers, once of which always contains zero, so we have at most 31 registers to work with. It has an internal counter that ticks once per two CPU clocks, which can be used to check code timings. Instruction timing follows the following rules, with a few exceptions and oddities:
An interesting side-note: on first pass, I was unaware of the Flash load delay rule, so the overall timing ended up being about 15% over spec, and all worked well. Only by trying to find some other bug did I find this out, by adding instruction timing counters to the code to track every part. This helped narrow down the wrong timing assumptions and end up with rock solid timing in all code paths.
We chose a 48 MHz clock, instead of the maximal 50 MHZ, since the UART top speed is ¼ of the clock speed, and a 12 MHz rate was much easier to find interface solutions than 12.5 MHz if we used the top speed of 50MHz. Plus the desired output rate aligned better to instruction boundaries (60 instructions per bit instead of 62.5 instructions).
Thus for each output bit period (1250ns) we had 60 clock cycles. We also needed to input data at a max rate of 12 Mbaud, which is 1,200,000 bytes per second (using 8N1 signaling), requiring an average of 1.5 bytes of input processed per 60 instruction block.
Luckily the PIC has an 8-byte deep FIFO queue on input (and output), allowing us some slack, but requiring that we check in often and on average fast enough to process all bytes.
Note that each output bit to a strand takes a few decision points: at the start, a pin has to go from low to high, then at the right time, a 0 or 1 is output on this pin to denote a 0 or 1, and at a later time the pin must be set to 0 always. Note the color bit can be output directly at the second point, avoiding some decision to be made with a branch to different code points, but at the cost of requiring writing the last 0 signal in all cases (which is redundant for the 0 bit). However this results in the least amount of instructions, but requires three writes per bit.
Thus, during each 120 instructions, we had to process 2 output writes (each is three possible high/low transitions) and input 3 bytes of serial input. This entailed:
So we have used approximately 102+24+5+4+4=139 instructions out of our budget of 120. Only 15% over budget, blah!
There is no way to write this in C; it had to be done in assembler.
The end protocol supports a synchronization byte, latching control, logs timing and flow data, had programmable delays, returns status bytes to the controller, supports strand widths of 1-16 and the maximal lengths in the above table, and even had a little space left over. The tightest parts ended up with 17 unused instruction slots out of 480, of which there were about 9 such blocks.
The way this was done involved a TON of tricks, the hardest one was writing a custom assembler that took templates of code, evaluated the timing and parametric parts, and then did a fitting algorithm that tried to find a solution to the needs of the output timing while meeting all the requirements we wanted. For example, branch paths had to take the same time in either part, lots of state was stored in code location (which duplicated some code paths, freeing registers and removing reads and writes), some clever table driven tricks, a completely non-obvious internal representation (sort of a meet-in-the-middle form of the input doing some work on transforming, and the output doing some of the work…. No other combination I tested would fit), using a dynamic register allocation scheme, and using some of the weirder MIPS instructions to squeeze every cycle out of the drawing routines. Here is a picture of the assembler I wrote, which color coded things, allowed jumps and timing info to be checked, and logged other interesting things I needed:

Code looked like this, with embedded timing info, symbols explaining branch sizes, symbols to be expanded and replaced locally and globally, and atomic blocks (which cannot be split when interleaving the pieces).
“C// do [COL]. “,
” lw r2,UARTSTA(r1) // byte ready? r1=UART base “,
“F lw r5,BITTABLE(r7) // get the bit expansion table. “,
” or r60,r2 // log any UART errors “,
” andi r2,r2,1 // ready mask “,
“{ beq r2,zero,[WAIT_X+] // exit to wait for byte. Note: next instruction always executed”,
” addi r3,zero,SYNCVAL // restore Sync value “,
“}[WAIT_R+] // Wait must return here”,
” lbu r2,UARTRX(r1) // get the data byte in r2, offset r1 to U1RXREG “,
” nop // todo – this can be anything “,
“{ bne r2,r3,[SYN_J+] // 1: if r2 != sync, continue with UART “,
” nop // 2: todo – can place optional stuff here? “,
” addiu r21,1 // 3: increment sync counter, always executed “,
” beq zero,zero,[SYN_X+] // 4: if sync byte (in r3), jump to sync operation “,
” sb r21,UARTTX(r1) // 5: output count, always executed in branch slot”,
“-3[SYN_R+] sll r2,2 // 3: multiply by 4 to get 4 32-bit table entries. Sync must return here “,
” add r2,r5 // 4: add table base (in r5) to reversed, packed entries “,
“} lw r3,[PASS_RAM](r4) // 5: get data to modify from RAM buffer “,
” addiu r5,255*4 // prepare to make bitmask mask”,
“F lw r5,(r5) // get inverse of bitmask “,
“F lw r2,(r2) // get table entry, with 8 bits of data, one per nibble. FLASH clock penalty “,
” nor r5,zero,r5 // invert to get bitmask “,
” and r3,r5 // zero eight bits from RAM “,
” or r3,r2 // or in eight bits from UART “,
” sw r3,[PASS_RAM](r4) // write all bits back to RAM buffer “,
The final output is a single routine consisting of about 8,000 lines of assembly code, a massive rat’s nest of gotos (no subroutines). It is so massive that trying to get the popular disassembler IdaPRO to make a flow graph it crashes the tool.
We ended up with a cheap device that can handle about 40 fps and 10,000 LEDs, as desired.
Enough about that.
During testing, we noticed that if you had a strand of about 240 LEDs in a row, powered from one end, and put it all on bright white (color 255,255,255), then the far end would be much dimmer than the powered end due to power draw. So it might be important to add power taps often to the LED strands to meet your needs. Some strands may vary.
Too get some idea of power draw, we measured draw on strands of lengths 1, 25,40, 100, and 240, and tested many color combinations including all combinations of 0 and 255 for R,G,B, and also R=G=B for values 0 to 255 in steps of size 16 (using 255 instead of 256). The conclusion is a good guideline is each LED draws around 10-13mA on full brightness, so a RGB module can draw up to 3*13=39mA, and this draw scales linearly with color value until about color 16, when it drops slightly more quickly to 0.
Shorter strands drew slightly more current per LED than longer strands; probably we were not driving some LEDs as bright as others due to length related dropouts.
For example, a strand of length 240 with red and green on full and blue on half should stay under 240*(13+13+13*128/255) = 7806 mA = 7.8A.
We have fried more LED modules than we cared to by connecting them wrong (mistakenly), so be careful. Some brands seem surprisingly fragile. We have found, though, if you fry a strand, cutting off the first one or two LEDs allows the rest of the strand to work, so you can treat the modules as $0.15 fuses if needed.
Signal voltages also drop along the length of a strand, and sometimes modules will miss bits if the power supply is not sufficient. If you’re having trouble with long strands, be sure to measure various components and ensure they meet specs. Signal voltages depend on the reference voltage powering the module, and we have found them somewhat tricky if you do not follow the specs carefully.
There still seems to be some weird power issues when building large strands, some of which we’ll detail below. If we get more solid knowledge and experience that clarifies the issues we’ll update this document.
When we started testing, we ran into some image issues at long (> 5,000) length strands. There was flickering, lost bits (resulting in shifting colors), and other behavior that made us wonder if the power was flaky or if the LED internal timings were causing problems.
Here is about 11,000 LEDs for testing our module design. Gene is in the process of making a cool cylindrical LED brain melter out of these at this point, for me to test the module on.

Our original timings were over by 15% due to the code penalty for flash reads, and after fixing this, using an internal counter to validate, we finally checked with an external logic analyzer to ensure our timings were perfect.
Some flickering persisted, and spending time determining if it was flaky power or our timing errors led us to some interesting analysis.
After testing the power we were led to believe the signals were corrupted, so we decided to look at the signals using a Seleae [Seleae] logic probe, which is an inexpensive 8-channel digital signal capture tool, capable of 24MHz sampling, which gives a timing resolution of 41.67 ns. We hooked the signals to the output from our device, which was at this point flawless, and then to various points on the LED strands. We found that the signal was indeed getting corrupted, but the behavior was sufficiently random and hard to reproduce that we deduced it was related to the signal shaping in the modules combined with clock fluctuations.
The behavior exhibited random noise, which made us wonder if there were an internal clock in each module, and if clock skew were adding up somehow and messing the signal up. We had read there was some form of signal shaping done by the LEDs from one to the next, and we wondered how this worked, and if it was somehow responsible, so we decided to try and measure it.
Since the modules are cheap, and behaved as if they were self-clocked (which turned out to be true, and is likely based on preceding models in the family stating their internal clock speeds), it seemed they’d use the cheapest clocks they could, which is likely some RC circuit like the old-school 555 timer [555]. These clocks have skew of a 1-10% based on manufacturing, component variance, temperature, and non-linarites based on power draw. The behavior was definitely worse when trying to update a bright strand than a dim strand, which could have been a power issue or a heat issue.
We used our module, which has programmable timings, to test the boundaries of timings, looking for where things fail. We captured signals between LEDs to investigate how the signal shaping was modifying or interfering with the signal.
We first captured data spread out on a few long strands, but trying to understand long strand behavior with only 8 taps was messy, so we went to an 8 LED strand, tapping the output of our module and the output of each of the first 7 LEDs, and the 8th LED showed the final color seen. We also got to use some neat standalone LEDs based on the WS2812, pictured below. This made adding taps easier.

Next we wrote a tool to analyze the data flows and related timings. All captures were done at 24MHz, the limit of the Seleae tool, (we would love to have a much higher rate!). For most of the tests we sent 16 LEDs of color down the line to see how longer signals were handled, even though we could only capture 8 LEDs of timing.
The next picture shows how each LED consumes 24 bits, then passes the rest through, leading to the stair step signal. The top row is our signal; the next 7 channels are outputs of successive LED modules. This is 16 LEDs worth of color 254,254,254 sent using 1250ns length bits and equally spaced timing cutoffs.

Here is a close-up. The top signal is the one we generate, then the signal cascades down. The next picture has green connectors tracking how a bit flows down the LEDs. Here is a bit highlighted, with each succeeding bit delayed by the LED modules as part of their signal shaping, each delay is around 200 ns (to be determined better soon). We noticed that the signal shaping was changing the lengths of the highs and lows a little, so we wanted to investigate that.

For each test we recorded all transitions, then counted the high lengths, low lengths, variations between the top bit (our generator) and the successive bits (LED module shaped), all sorts of timing information like cascade delays, missing bits, how lengths changed as they moved from one LED to the next, etc. As we gathered more insight we added more analysis capability until we answered (almost) all of our questions.
Before we detail things we found, it might be best to give the final understanding we have, so you can follow along. We’ll then cover the measurements that led us to this model of the WS2812 LED modules.
This figure shows how we think of the timings the LED modules follow.

Figure 1- Timing Labels
| Symbol | Description | Length |
| b | Bit length | Varies based on input, always > 800ns or so. |
| h | High part for a 0 bit | 382 ns |
| m | Medium part, for a 1 bit | 382 ns |
| w | Low part, needed to set next high part | As low as we could measure, perhaps < 1ns. Follows from b=h+m+w |
| d | Delay between input and pass-through | 206 ns |
| s | Time when sample is taken | d+h=588ns |
| L | Minimum latch time | 9370 ns |
Figure 1 shows what we think is an accurate model of how the LEDs behave. The model is based on the measurements and experiments we do below.
The LED modules act as follows:
We labeled the data runs in the form G-R-B-H-M-L, where G, R, and B are the byte colors sent in that order (shows up as GRB). The H, M, and L were the lengths of the high part, the optional middle part, and the low part making the total bit length. The H, M, L values are PIC32 instruction counts, so each value is 125/6=21.8333… nanoseconds. A total length of 60 is thus 1250ns, the recommended bit length. 20-20-20 timing is equally spaced, and seems to work fine for strands up to a few thousand in length. We considered converting numbers to nanoseconds, but this implies more timing precision than we could accurately measure or create. All measured counts are at 24MHz, the sampling rate of the logic analyzer, so each measured tick is 125/3=41.6666…. Sorry for the multiple value sizes, but this keeps all inputs and outputs as measured, and we write the conclusion in nanoseconds. Hopefully each usage will be clear from context.
We experimented with all sorts of bit patterns and timing combinations, recording tens of thousands of bit cascades. Our custom analyzer then extracted the data so we could analyze it visually and numerically and test hypotheses against the information. This led to more tests to refine our ideas. Here we record the conclusions and some relevant data.
For many tests, we used 255-0-170 as a bit pattern with a good mix of 0’s, 1’s, runs, and transitions. To test high bits we sent 255-255-255 colors, and 0-0-0 for low bit studies. We often used 254-254-254 to see if bits were lost while allowing eyeballing of byte ends.
All errors we were able to uncover were of one type, which was a module missing the low to high transition of a parent, and then waiting until the next low to high happened, effectively losing a bit in the sequence. This can happen when the input bits are too short, but also happens as variation in clock skew along the strand sometimes bunches bits too close together.
For example, when we shortened the overall bit length to 255-0-170-20-20-14 (which corresponds to a total bit length of 1125ns, but with 433ns length high and middle parts), the test dropped some bits, but only after the first 8 LEDs obtained the correct colors. Here is a screen capture showing a bit getting squeezed out in the lower 2 strands.

At 20-20-10 timing, errors are rampant. You can see many dropped bits. Here are some stats: top bit lengths 25 (except two of them are 26), Top bit high are good, top bit low are short (5,6 and 15,16).

We investigated a large range of timing and bit combinations, always fine tuning the tests around edge cases where things went wrong. From all the timings, we saw that several components of the LED timing were relatively constant: the length of high parts for the 0 and 1 bits, and the inter-LED delay. Across 13605 short high bit samples, we saw an average of 9.18 (382.6 ns) with min of 8 and max of 11, so we conclude that h should be 382.6 ns. Across 16632 long high bit samples, we saw an average of 18.34 (764.3 ns) with a min of 17 and a max of 21. Thus we conclude that m should be 764.3-382.6=381.7 ns. Note this is very close to the short bit. Coincidence? Probably not. For the inter-LED delay, across 36999 samples we got an average of 4.95 (206.2 ns), with a min of 2 (only 3 samples, this needs more checking) and a high of 7 (only 7 samples). The majority (36771/36999=99.38%) were in lengths 4-6. Thus d should be around 206.2.
These timings are a bit longer than some reported at [Beaklow], who measured a single LED. Perhaps we’re using different manufacturers, or even seeing variations in batches.
We note that the datasheet has a stated transmission delay time max of 300 ns; we have seen no events even near this long, and we obtained 206 ns as a very good value for the propagation delay. At 206 ns, a 10,000 long strand should propagate a signal in around 2 milliseconds, which is around 1/485 of a second.
A quick note on statistics: the underlying internal clocks can be modeled as a Gaussian (normal) distribution around the central clock rate, and likely temperature and manufacturing and ageing cause some variance in the clock rate. However we can only measure on discrete boundaries, which means we’re measuring the normal plus a uniform (spread over 1 tick length). However, the mean of the Gaussian is still the mean of the measured lengths (check it), so talking about averages (technically, means) is sufficient. A better model would take into account variations induced by temperature and power draw, which is a function of history and needs more data. We think there is some power or temperature component to the behavior, but we have not isolated it.
The overall bit lengths are dependent on the top signal – when we lengthened the input bit length to around 1800 ns, everything transmitted fine, and each child bit just lengthened the low part of the signal. The above timings were all still stable. When we shortened the bits as low as 800 ns, the modules lost every other bit, but again the numbers above stayed stable for the bits obtained. So this provides evidence against the modules obtaining clocking from the input signal, and implies an internal clock, as expected. We were able to drop the bit length to around 1150 and keep the other lengths and still work for our 8 LED test bench, but we expect longer strands will fail.
From the way bits are dropped, it appears that once a bit is started, the module ignores transitions on input until the module has finished with its bit processing, so there is a minimum bit time. Again, across all the many tests we ran, we observed that the longest bit length that was dropped was 19 (7 occurrences, 199 occurrences for length 18, many for even shorter), and the shortest bit that was passed correctly was also 19 (1 occurrence, 12 of length 20, and 301 of length 21, out of 47403). This implies that the shortest bit possible for one module to transmit to the next module is around length 19 (791.7 ns) or 20 (833.3 ns).
The shortest low part seen was 1 tick, but we recorded several events where the high part seemed to be multiple ones concatenated together, meaning we did not capture the drop to low and subsequent rise to high. This means that the high to low and low to high can be below 1 tick (41.66 ns) and still transmit, but it’s asking for trouble.
Low length for the child bits were all over the map, so it is unlikely that these are clocked by the modules. They seem to depend only on the input timings.
To determine when the sampling to differentiate a 0 from a 1 bit takes place (or if there is multisampling and majority vote, or some other scheme), we had our software analyze all transitions to determine how it looked, and we found a few events such as this:

Here the top bit drops high to low at tick 9227, and the child bit drops at 9227 also. So the module had to be sent a low at this tick, and in the same tick, it dropped its output. The bit started on tick 9218, so after 9 ticks it looked at its input and set the output to that value. (It could not have sampled sooner or it would have seen a high. It certainly could not sample later than its output transition).
Thus sampling seems to occur once at the end of the high length h, and the output is done immediately. At a design level this saves having to store the sample and output later, so makes sense for simplicity.
Finally, we timed the minimum latch length as follows. We put a dynamic pattern on the LEDs, and shortened the latch time until the image flickered, meaning it was not latching correctly. We found that we obtained stable images using a latch length of 9375 ns, and an unstable image at 9333 ns. Again, we sampled with the logic analyzer, so we’re accurate to within 41.666… ns. Datasheets recommend 50,000 ns, so we suspect you can go much lower and still perform well.
So we have evidence for all the numbers and behavior in out model.
There was one last really odd behavior we could not figure out. With perfect 20-20-20 timing, well within spec, and the 8 LEDs above, we noticed that sending the same color to each channel (such as 255-255-255) and then waiting would cause all the LEDs to go black after a while (1-5 seconds). This only happened if all three colors were the same, testing 255-255-254 would not do it. It happened at 1-1-1 color, 5-5-5 color, 254-254-254 color, and any other combinations we tested had the same behavior. If the colors were different, then there was no cutoff (we tested to 60 seconds in each case). 1-1-0 and other combinations did not do it. The cutoff times were all in the 1-7 second range, with one outlier taking 11 seconds. This was all at 5 V power. At 7V power it did not happen. When we added a 0.1uF capacitor to the far end of the chain, it went away. During all this we collected signal traces, and saw no anomalies or signals between the LEDs after they were latched.
So – is there some weird design bug where the same value on all channels causes power instability? We don’t yet know.
The modules appear to have an internal clock, and it seems likely that the simplest circuit showing the behavior we observed is the circuit used. As such, it seems a low to high transition starts a counter, and at certain counts different actions are taken. A 200ns delay requires around a 5MHz clock, quite a bit faster than the supposed 1.2MHz. To make the whole thing run on the slowest clock possible would require the other events (d=206, h=382, m=382, s=588) to be integral multiples of the smallest, and they are close.
For example, if we took d=191, h=382, m=382, s=573, and a clock rate of 5.235MHz, then on clock ticks 1,2,3,4 the various events would happen, all on successive ticks. Nice, huh? But it requires a fast clock, and is the non-illuminating multiple 4.36 of the 1.2MHz suspected clock…. Of course all the timing may just be CMOS delays, with no high speed clock needed. It would be interesting to know.
For a final try to gather some clock information, we could record various color outputs at 30fps (or higher if possible), mess with the color values, and try to determine the LED pulse width modulation frequencies. We could play different values on the three channels against each other, obtaining “beats” like one does when tuning a piano. The PWN likely works as follows (since it is simple in hardware). The color c for a channel is added periodically to an 8-bit counter, and on overflow the LED is turned on, else it is turned off. Adding color 0 will never overflow, so never turn on. Color 1 will overflow 1 out of 256 ticks, so be on 1/256 of the time. Color 128 will overflow every other tick, so be on half the time. Color 255 will overflow 255 times out of 256, so will be on all but 1 tick out of 256. Ideally we’d like the 255 on all the time, but the minimal circuit for that (that still handles the other cases nicely) is much more complicated. It would be fun to see if this hypothesis is true by determining flicker at color 255 (with a FAST camera), and thereby measuring the speed. I played a little with a 240 fps Canon S100, but have not reached any conclusions, other than I do see the PWM at work on lower colors.
We obtained pretty solid evidence on how the signal shaping of the WS2811/WS2812/WS2812B modules work, and will use this knowledge to fix the flicker on long strands (over 5,000, up to 10,000 modules). There is still some work that can be done to figure out the internal clock rates as well as try to measure clock variability, skew with current/temperature/history.
We’re getting ready to test some of these ideas on getting stable 10K long strand images (just to see if it works!), and will post results.
If you find errors or have more information to add, let us know, and we’ll add it to this document.
Thanks for reading this long write-up.
[555] http://www.ti.com/lit/ds/symlink/lmc555.pdf
[Adafruit] http://www.adafruit.com/
[Alibaba] http://www.alibaba.com/trade/search?SearchText=ws2812
[Beaklow] http://bleaklow.com/2012/12/02/driving_the_ws2811_at_800khz_with_a_16mhz_avr.html
[FTDI] http://www.ftdichip.com/
[Gamma] http://rgb-123.com/ws2812-color-output/
[PJRC] http://www.pjrc.com/teensy/td_libs_OctoWS2811.html
[Saleae] http://www.saleae.com/logic/
[Semi] http://www.world-semi.com/ [world semi]
[SparkFun] https://learn.sparkfun.com/tutorials/ws2812-breakout-hookup-guide/ws2812-overview
[TM1804] http://www.titanmec.com/doce/product-detail-172.html
[TM1809] http://www.titanmec.com/doce/product-detail-171.html
[WS2811] http://www.world-semi.com/en/Driver/Lighting_LED_driver_chip/WS2811/
[WS2812] http://www.adafruit.com/datasheets/WS2812.pdf
[WS2812B] http://www.mikrocontroller.net/attachment/180459/WS2812B_preliminary.pdf
[WS2812+WS2812B] http://www.mikrocontroller.net/attachment/180460/WS2812B_VS_WS2812.pdf
